From JOSM search & replace to processing Openstreetmap with your favorite text edition tools
There you are, in some Openstreemap editor, correcting the same typo for the 16th time, cursing contributors who neglect correct capitalization and thinking about how tedious this necessary data gardening is. While JOSM is endowed with unfathomable depths of cartographic potentiality, you long for a way to simply whip out your favourite text editor and apply its familiar power to the pedestrian problem of repeatedly editing text. Or the problem requires editing multiple mutually dependent tags and some XML-aware logic is therefore required – all the same: you just want to perform Openstreetmap editing as text processing.
Of course, as an experienced Openstreetmap gardener, you are well aware of the dangers of casually wielding a rather large chainsaw around our burgeoning yet fragile data nursery. So you understand why automated processing is generally not conducive to improvement in data quality – rare is the automation whose grasp of context equals human judgment. But human judgment could use some power tools… So there.
My overall workflow shall be as follow:
0 – Read the Automated Edits code of conduct
1 – Get data
2 – Edit data
3 – Review data
4 – Commit data
The meticulous reader might object that making the reviewing an explicit step separate from the editing is superfluous since no self-respecting cartographer would commit edited data without having performed a review as a mandatory step integral to edition. But the reader who closely observes Openstreetmap activity might counter that this level of self-disciplined care might not be universal, so the step is worth mentioning. Moreover, I’ll add that as soon as any level of automation is introduced, I consider the reviewing as a necessary checklist item.
So, first let’s get the data ! There are many ways… The normal JOSM way of course – but your mass edition requirement probably means that you wish to edit a body of data much larger than what the Openstreetmap servers will let JOSM download at once – and, if you ever had to repeatedly download rectangles until you have covered you whole working area, you don’t want to do it again.
To illustrate this article, I chose to edit places of worship in Senegal (I am a rather active Openstreetmap contributor for Senegal and places of worship are socially and cartographically important landmarks). This dataset is rather small – in such cases you might want to peruse Overpass Turbo. The relevant Overpass Turbo query is as follow:
[out:xml][timeout:25];
{{geocodeArea:Senegal}}->.searchArea;
(
node["amenity"="place_of_worship"](area.searchArea);
way["amenity"="place_of_worship"](area.searchArea);
relation["amenity"="place_of_worship"](area.searchArea);
);
out meta;
>;
out meta qt;
Another option, viable even for targeting the whole planet, is to use Osmosis (package available from good distributions) to filter a planet extract:
wget http://download.geofabrik.de/africa-latest.osm.pbf osmosis \ --read-pbf file=africa-latest.osm.pbf \ --bounding-box top=16.7977 bottom=12.0832 \ left=-17.6317 right=-11.162 \ --tag-filter accept-nodes amenity=place_of_worship \ --tag-filter reject-relations \ --tag-filter reject-ways outPipe.0=nodesPipe \ --read-pbf file=africa-latest.osm.pbf \ --bounding-box top=16.7977 bottom=12.0832 \ left=-17.6317 right=-11.162 \ --tag-filter accept-ways amenity=place_of_worship \ --tag-filter reject-relations \ --used-node outPipe.0=waysPipe \ --merge inPipe.0=nodesPipe inPipe.1=waysPipe \ --write-xml senegal-place_of_worship.osm
Yes, I didn’t take relations into account – there are only a couple of amenity=place_of_worship relations in Senegal’s Openstreetmap data… So adding relations to this query is left as an exercise for the reader.
A gigabyte download and a couple of minutes of osmosis execution later, your data is ready and you have found new appreciation of how fast Overpass Turbo is. Our Osmosis computation might have been a little faster if there was a Senegal planet extract available, but we had to contend with taking the whole of Africa as an input and filtering it through a bounding box.
By the way, the dedicated reader who assiduously tries to reproduce my work might notice that the two methods don’t return the same data. This is because the Overpass Turbo query filters properly by intersection with Senegal’s national borders whereas my Osmosis command uses a rectangular bounding box that includes bits of Mauritania, Mali, Guinea and Guinea Bissau. One can feed Osmosis a polygon produced out of the national borders relations, but I have not bothered with that.
Examples OSM XML elements extracted by the osmosis query:
<way id="251666247" version="2" timestamp="2014-03-27T22:16:56Z"
uid="160042" user="Jean-Marc Liotier" changeset="21354510">
<nd ref="2578488987"/>
<nd ref="2578488988"/>
<nd ref="2578488989"/>
<nd ref="2578488990"/>
<nd ref="2578488991"/>
<nd ref="2748583071"/>
<nd ref="2578488987"/>
<tag k="name" v="Grande mosquée de Ndandia"/>
<tag k="source" v="Microsoft Bing orbital imagery"/>
<tag k="amenity" v="place_of_worship"/>
<tag k="religion" v="muslim"/>
<tag k="denomination" v="sunni"/>
</way>
<node id="2833508543" version="2" timestamp="2014-09-01T09:57:07Z"
uid="160042" user="Jean-Marc Liotier" changeset="25155955"
lat="14.7069108" lon="-17. 4580774">
<tag k="name" v="Mosquée Mèye Kane"/>
<tag k="amenity" v="place_of_worship"/>
<tag k="religion" v="muslim"/>
</node>
<node id="2578488987" version="1" timestamp="2013-12-13T17:49:40Z"
uid="1219752" user="fayecheikh75" changeset="19436962"
lat="14.2258174" lon="-16.8134644"/>
The first two example OSM XML elements will not come as a surprise: they both contain <tag k=”amenity” v=”place_of_worship”/> – but what about the third, which does not ? Take a look at its node id – you’ll find it referred by one of the first example’s <nd /> elements, which means that this node is one of the six that compose this way. Including nodes used by the ways selected by the query is the role of the –used-node option in the osmosis command.
But anyway, why are we including nodes used by the ways selected by the query ? In the present use-case, I only care about correcting trivial naming errors – so why should I care about the way’s geometry ? Well… Remember the step “3 – Review data” ? Thanks to being able to represent the way geometrically, I can visually find that an English-language name may not be an error because the node that bears it is located in Guinea Bissau, not in Senegal where it would definitely be an error outside of the name:en tag. Lacking this information I would have erroneously translated the name into French. Actually, I first did and only corrected my error after having reviewed my data in JOSM – lesson learned !
Talking about reviewing, is your selection of data correct ? Again, one way to find out is to load it in JOSM to check tags and geographic positions.
And while in JOSM, you might also want to refresh your data – it might have become stale while you were mucking around with osmosis (do you really think I got the query right the first time ?) and Geofabrik’s Planet extracts are only daily anyway… So hit Ctrl-U to update your data – and then save the file.
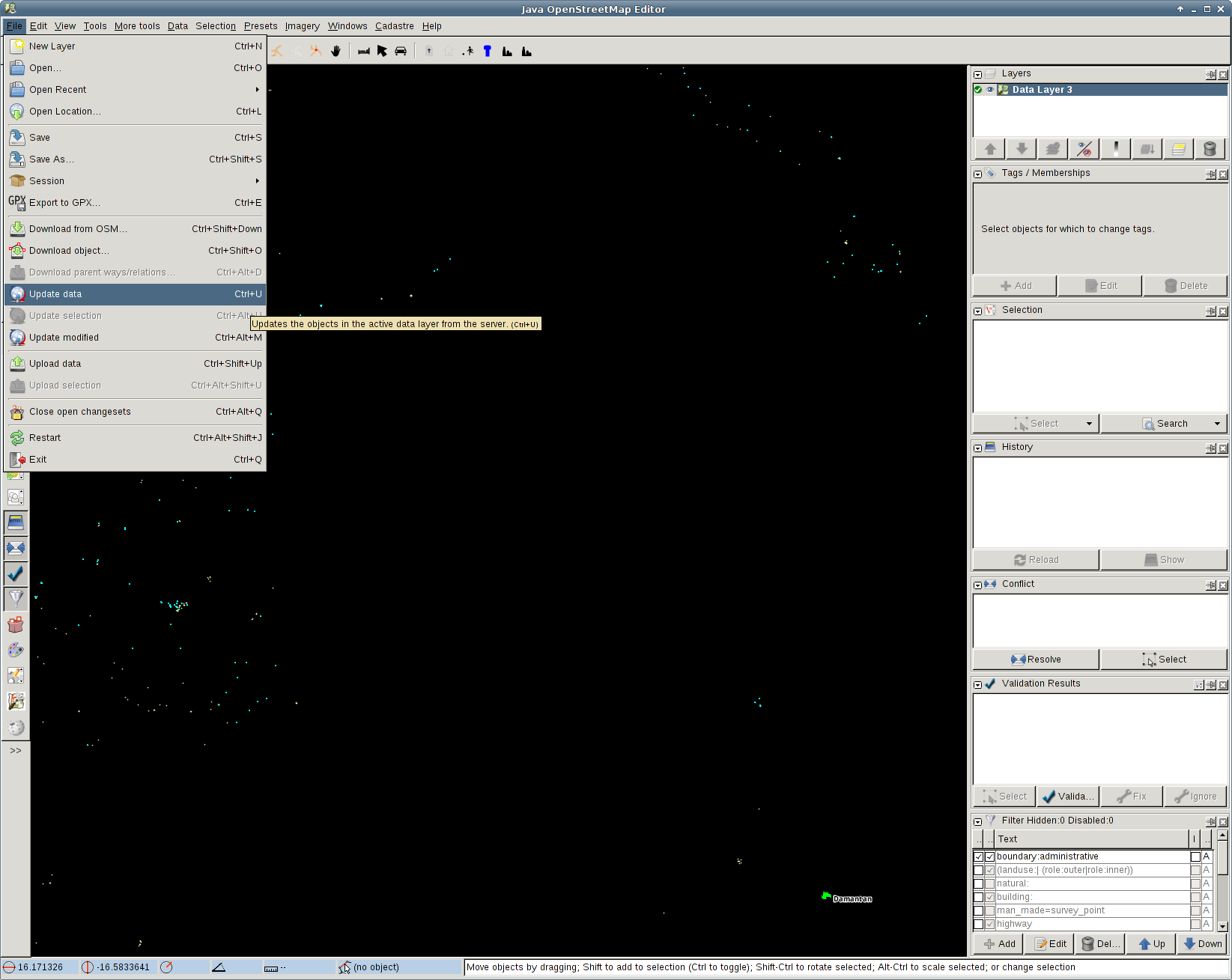
This concludes step “1 – Get data” – let’s move on to step ‘2 – Edit data’ ! First, do not edit the file you just saved: we will need it later to determine what we have modified. So produce a copy, which is what we’ll edit – execute ‘cp senegal-place_of_worship.osm senegal-place_of_worship.mod.osm’ for example.
Now take your favourite text processing device and go at the data ! I used Vim – here is how it looks like:
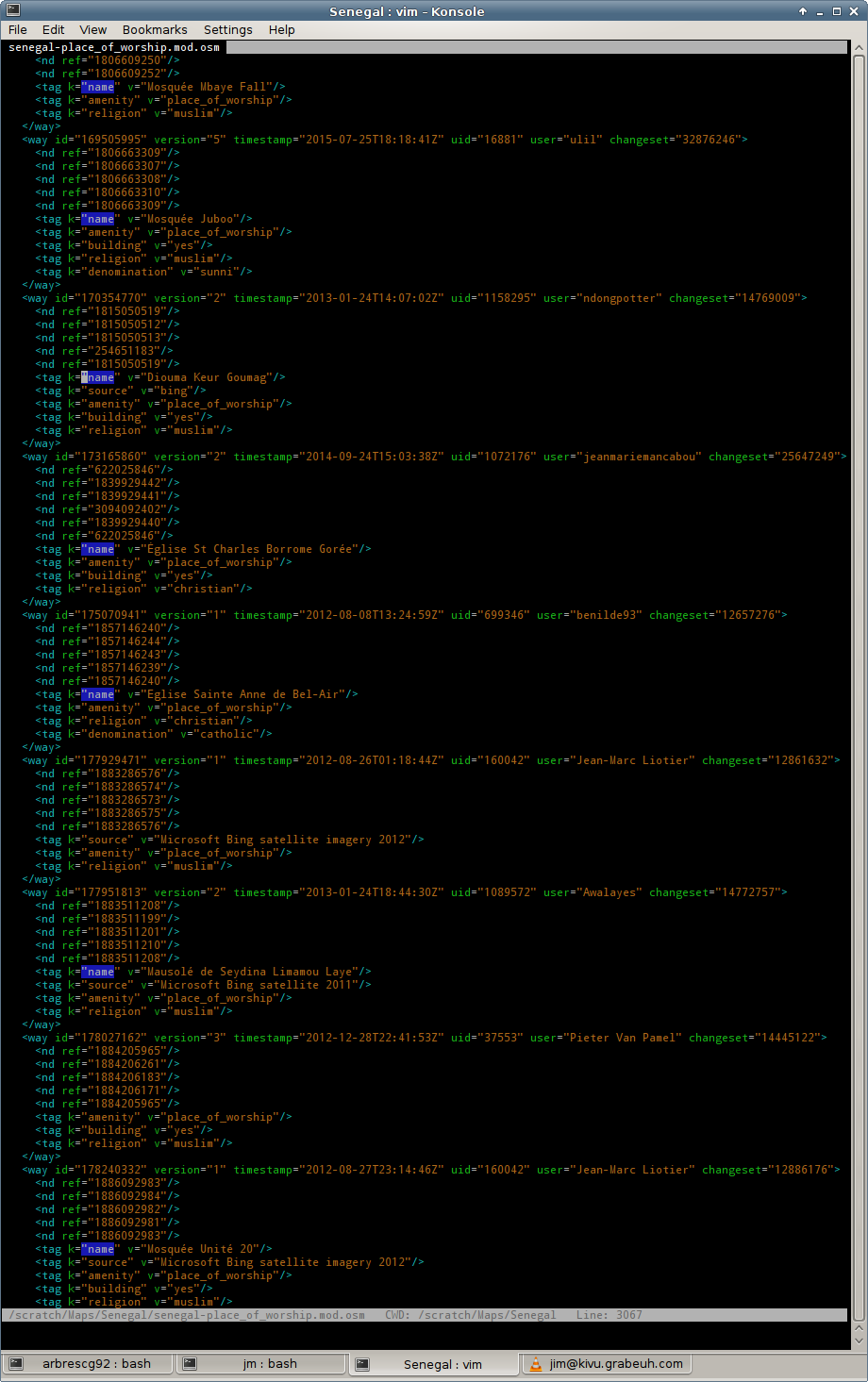
A few edits later:
$ diff -U 0 senegal-place_of_worship.osm senegal-place_of_worship.mod.osm \ | grep ^@ | wc -l 164
As an example of modification, let’s have a look at this node :
<node id="2165307529" version="1" timestamp="2013-02-21T13:40:05Z"
uid="1234702" user="malamine19" changeset="15112373"
lat="16.0326014" lon="-16.5084412">
<tag k="name" v="Mosquée Sidy TALL"/>
<tag k="amenity" v="place_of_worship"/>
<tag k="religion" v="muslim"/>
</node>
A few keystrokes later, its name’s capitalization is fixed :
<node id="2165307529" version="1" timestamp="2013-02-21T13:40:05Z"
uid="1234702" user="malamine19" changeset="15112373"
lat="16.0326014" lon="-16.5084412">
<tag k="name" v="Mosquée Sidy Tall"/>
<tag k="amenity" v="place_of_worship"/>
<tag k="religion" v="muslim"/>
</node>
Let’s open the file in JOSM and upload this awesome edit to Openstreeetmap – here we go !
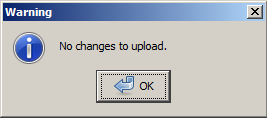
“Whaaat ? No changes to upload ? But where are my edits ? You said we could just edit and upload !” – No, and anyway I said that you had to review your data beforehand !
Fear not, your edits are safe (if you saved them before closing your editor…) – it is only JOSM who does not know which objects you edited. Looking at the above data, it has now way to determine if any part has been edited. We’ll have to tell it !
When JOSM modifies any element of an Openstreetmap object, it marks the Openstreetmap object with an action=”modify” attribute. So, we’ll emulate this behaviour.
“Whaaat ? Do I really have to write or copy/paste action=”modify” on the parent Openstreetmap object of every single modification ? You said this article was about automation !” – fear not, I have you covered with this article’s crowning achievement: the OSMXML_mark_modified_JOSM-style script.
Remember when I’ll said earlier “First, do not edit the file you just saved: we will need it later to determine what we have modified. So produce a copy, which is what we’ll edit – ‘cp senegal-place_of_worship.osm senegal-place_of_worship.mod.osm’ ” ? We are now later and the OSMXML_mark_modified_JOSM-style script will not only determine what we have modified but also mark the parent Openstreetmap object of each modification with an action=”modify” attribute.
This blog needs a wider stylesheet, so no inline code in the article – read OSMXML_mark_modified_JOSM-style on Github instead and save me the paraphrasing of my own code ! This script owes everything to XML::SemanticDiff and XML::LibXML – it is a mere ten-line conduit for their blinding awesomeness so all credits go to Shlomi Fish and Kip Hampton.
So, just make sure that you have XML::SemanticDiff and XML::LibXML installed from the CPAN or preferably from your distribution’s packages and execute the command line:
OSMXML_mark_modified_JOSM-style \
originalOSMfile.xml \
locally_modified_originalOSMfile.xml
or in our current example
OSMXML_mark_modified_JOSM-style \
senegal-place_of_worship.osm \
senegal-place_of_worship.mod.osm
As a result, the parent Openstreetmap object of each modification will have been marked with an action=”modify” attribute – as our example object:
<node id="2165307529" version="1" timestamp="2013-02-21T13:40:05Z"
uid="1234702" user="malamine19" changeset="15112373"
lat="16.0326014" lon="-16.5084412" action="modify">
<tag k="name" v="Mosquée Sidy Tall"/>
<tag k="amenity" v="place_of_worship"/>
<tag k="religion" v="muslim"/>
</node>
Now open the modified file in JOSM and review the result. As I mention in passing in the script’s comments: BLOODY SERIOUSLY REVIEW YOUR CONTRIBUTION IN JOSM BEFORE UPLOADING OR THE OPENSTREETMAP USERS WILL COME TO EAT YOU ALIVE IN YOUR SLEEP ! Seriously though, take care : mindless automatons that trample the daisies are a grievous Openstreetmap faux pas. The Automated Edits code of conduct is mandatory reading.
Ok, I guess you got the message – you can now upload to Openstreetmap:
If you spent too long editing, you might encounter conflicts. Carefully resolve them without stepping on anyone’s toes… And enjoy the map !
Incidentally, this is my first time using XML::LibXML and actually understanding what I’m doing – I love it and there will be more of that !